Một trong những chuyên gia ‘của Grammarly đang kiện công ty về tính năng AI đánh cắp danh tính
Grammarly đối mặt vụ kiện liên quan đến việc sử dụng nội dung trong hệ thống AI
Grammarly đang đối mặt với một vụ kiện mới liên quan đến cách công ty sử dụng dữ liệu để phát triển các công cụ trí tuệ nhân tạo của mình. Vụ kiện được đưa ra bởi nhà báo Julia Angwin, người cho rằng nội dung của bà đã bị sử dụng trong hệ thống AI của Grammarly mà không có sự cho phép.
Theo đơn kiện, Angwin cáo buộc Grammarly đã sử dụng nội dung từ các bài viết của bà để huấn luyện hoặc cải thiện các tính năng AI. Bà cho rằng việc này diễn ra mà không có sự đồng ý rõ ràng từ phía tác giả và có thể vi phạm quyền sở hữu trí tuệ.
Grammarly là một trong những công ty nổi tiếng trong lĩnh vực công cụ hỗ trợ viết. Dịch vụ của hãng sử dụng trí tuệ nhân tạo để kiểm tra chính tả, ngữ pháp và đưa ra gợi ý cải thiện văn bản. Trong những năm gần đây, công ty đã mở rộng mạnh mẽ các tính năng AI nhằm hỗ trợ người dùng viết nội dung hiệu quả hơn.
Vụ kiện đặt ra câu hỏi về cách các công ty AI thu thập và sử dụng dữ liệu để huấn luyện hệ thống của họ. Khi các mô hình AI ngày càng phụ thuộc vào lượng lớn văn bản từ internet, nhiều tác giả và nhà báo đã bày tỏ lo ngại rằng nội dung của họ có thể bị sử dụng mà không có sự cho phép hoặc bồi thường.
Tranh chấp giữa các nhà sáng tạo nội dung và công ty công nghệ đang trở nên phổ biến hơn khi AI phát triển nhanh chóng. Các vụ kiện như vậy có thể góp phần định hình các quy định pháp lý mới liên quan đến quyền tác giả và việc sử dụng dữ liệu trong hệ thống trí tuệ nhân tạo.
Kết quả của vụ kiện có thể ảnh hưởng đến cách các công ty AI xây dựng và đào tạo các mô hình trong tương lai, cũng như cách họ làm việc với các nhà xuất bản và tác giả nội dung.



Bài viết liên quan
AI là sự kết thúc của công nghệ phần mềm hay bước tiếp theo trong quá trình phát triển của nó?
“Vibe coding” và cách AI đang thay đổi tương lai của lập trình Sự phát triển nhanh chóng của trí tuệ ...

Tôi đã nhìn thấy tương lai của ngành bán lẻ, và tất cả đều là AI
AI đang thay đổi cách các nhà bán lẻ vận hành và tiếp cận khách hàng Tại sự kiện National Retail ...
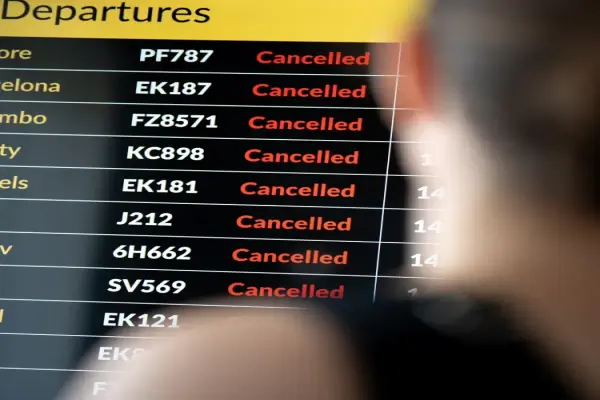
Cuộc chiến của Trump với Iran đã khiến một triệu tờ rơi — mắc kẹt như thế nào và khiến sân chơi yêu thích của vùng Vịnh rơi vào hỗn loạn
Chiến sự Iran khiến nhiều chuyến bay đến Dubai bị hủy và làm gián đoạn hoạt động sân bay Xung đột ...
Tin đồn iPhone Fold: Đa nhiệm giống iPad, nhưng không có ứng dụng iPad và không có Face ID
Tin đồn iPhone màn hình gập có thể mang trải nghiệm đa nhiệm giống iPad Apple được cho là đang phát ...

Một số trò chơi kinh dị hay nhất từng được thực hiện được bao gồm trong gói 15 đô la mới nhất của Humble
Humble Bundle giảm giá loạt game kinh dị Amnesia và SOMA của Frictional Games Một gói khuyến mãi mới ...

Valve nói rằng họ sẽ chống lại vụ kiện loot box của New York
Valve đối mặt vụ kiện liên quan đến loot box trên Steam và các trò chơi như Dota 2 và Team Fortress ...