Bất Ngờ: Claude Opus 4.1 Đánh Bại GPT-5, Gemini và Grok Trong Các Nhiệm Vụ Công Việc Thực Tế (Nghiên Cứu của OpenAI)
Claude Xuất Sắc Đánh Bại GPT-5, Gemini và Grok Trong Nhiệm Vụ Công Việc Thực Tế
Một nghiên cứu mới gây ngạc nhiên từ chính OpenAI – công ty tạo ra ChatGPT – cho thấy mô hình Claude Opus 4.1 của đối thủ Anthropic đã vượt qua cả GPT-5 cùng với Gemini và Grok trong các nhiệm vụ công việc đời thực.

Hệ Thống Đánh Giá Mới: GDPval
Để khắc phục hạn chế của các tiêu chuẩn AI truyền thống (vốn thường không phản ánh cách mọi người thực sự sử dụng AI tại nơi làm việc), OpenAI đã giới thiệu hệ thống đánh giá mới mang tên GDPval.
Mục tiêu: GDPval đo lường hiệu suất của các mô hình AI trong các nhiệm vụ công việc thực tế (real-world work tasks) so với các chuyên gia con người trong 44 ngành nghề khác nhau, từ nhà phát triển phần mềm, luật sư đến y tá và kỹ sư.
Tên gọi: Tên GDPval được lấy cảm hứng từ Tổng sản phẩm quốc nội (GDP) như một chỉ số kinh tế quan trọng.
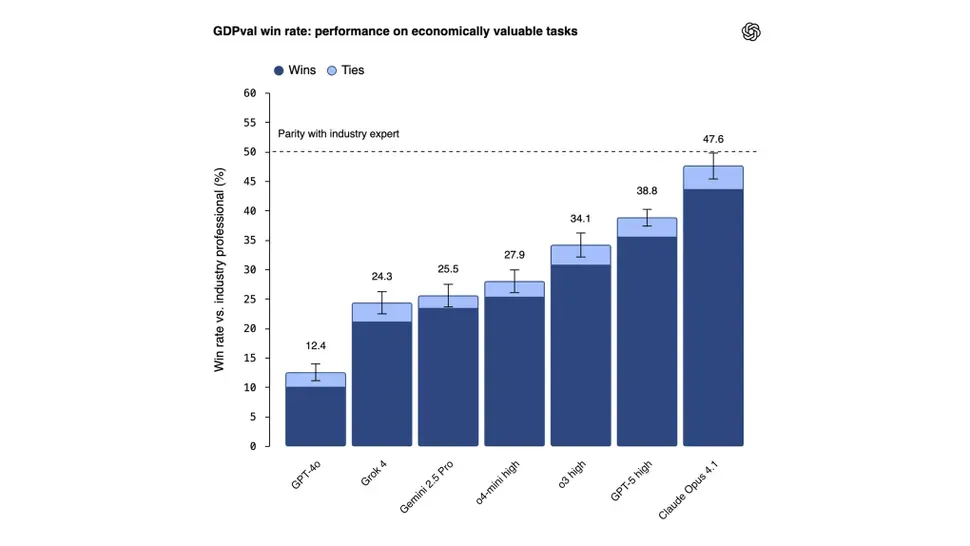
Kết Quả Bất Ngờ: Claude Lên Ngôi
Kết quả từ nghiên cứu của OpenAI cho thấy một bất ngờ lớn:
Thống trị ngành: Claude Opus 4.1 đạt hiệu suất cao nhất trên tám trong số chín lĩnh vực được thử nghiệm, bao gồm chính phủ, chăm sóc sức khỏe và hỗ trợ xã hội.
Ví dụ nhiệm vụ: Các nhiệm vụ thử nghiệm bao gồm soạn email phản hồi cho khách hàng không hài lòng, tối ưu hóa bố cục bảng cho hội chợ nhà cung cấp, và kiểm tra tính nhất quán về giá trong đơn đặt hàng.
Tính Minh Bạch Triệt Để của OpenAI
Việc OpenAI công bố một nghiên cứu cho thấy đối thủ cạnh tranh dẫn đầu có vẻ là một động thái gây ngạc nhiên, nhưng nó hoàn toàn phù hợp với triết lý của công ty:"Sứ mệnh của chúng tôi là đảm bảo trí tuệ nhân tạo tổng quát (AGI) mang lại lợi ích cho toàn nhân loại. Là một phần của sứ mệnh đó, chúng tôi muốn truyền đạt một cách minh bạch về tiến trình các mô hình AI có thể giúp đỡ mọi người trong thế giới thực như thế nào," tuyên bố từ OpenAI cho biết.
Kết quả nghiên cứu, được thực hiện bởi nhóm Nghiên cứu Kinh tế của OpenAI và nhà kinh tế học David Deming của Harvard, cho thấy hiệu suất thực tế của AI tại nơi làm việc khác xa so với các điểm chuẩn thông thường. Điều này có thể thúc đẩy OpenAI tập trung hơn vào việc cải thiện hiệu suất công việc thực tế, thay vì chỉ tập trung vào các tính năng hoặc chỉ số lý thuyết.
Bạn nghĩ liệu thành công này của Claude có khiến Anthropic trở thành lựa chọn hàng đầu cho các tác vụ doanh nghiệp trong tương lai không?



Bài viết liên quan

Wacom One
Wacom One 14: Bảng vẽ màn hình 14 inch cho người mới bắt đầu Wacom vừa ra mắt mẫu Wacom One 14 , ...
Tai nghe Galaxy mới nhất của Samsung đi kèm với thiết bị theo dõi Galaxy SmartTag2 miễn phí
Tai nghe Galaxy mới nhất của Samsung đi kèm với thiết bị theo dõi Galaxy SmartTag2 miễn phí Samsung ...
Vì sao Canva AI Image Generator là công cụ tôi luôn khuyên dùng cho người mới bắt đầu
Canva AI Image Generator – Công cụ AI lý tưởng cho người mới bắt đầu Canva từ lâu đã được nhiều ...

3 Nâng Cấp Camera iPhone 17 Pro Được Kỳ Vọng Sẽ Cân Bằng Lại Cuộc Chơi
(Nguồn ảnh: Future | Alex Walker-Todd) Mặc dù dòng iPhone Pro đã nổi tiếng về khả năng quay video và ...

Camera An Ninh Tốt Nhất cho Doanh Nghiệp 2025
Thị trường camera an ninh thương mại đòi hỏi các giải pháp vượt trội so với camera gia đình thông ...

Hoa Kỳ và Trung Quốc cuối cùng có thể có một thỏa thuận TikTok
🗓️ Thỏa thuận sơ bộ giữa Mỹ và Trung Quốc về TikTok Vào ngày 15 tháng 9 năm 2025, Bộ trưởng Tài ...