Bất cứ ai đã lướt web một thời gian có lẽ đã quen với việc nhấp qua lưới hình ảnh đường phố CAPTCHA, xác định các vật thể hàng ngày để chứng minh rằng họ là con người chứ không phải bot tự động. Tuy nhiên, hiện nay, nghiên cứu mới tuyên bố rằng các bot chạy cục bộ sử dụng các mô hình nhận dạng hình ảnh được đào tạo đặc biệt có thể phù hợp với hiệu suất ở cấp độ con người theo phong cách CAPTCHA này, đạt được tỷ lệ thành công 100% mặc dù rõ ràng không phải là con người.
ETH Zurich Nghiên cứu sinh Andreas Plesner và các đồng nghiệp của ông’ nghiên cứu mới, có sẵn dưới dạng giấy in sẵn, tập trung vào ReCAPTCHA v2 của Google, thách thức người dùng xác định hình ảnh đường phố nào trong lưới chứa các mục như xe đạp, lối băng qua đường, núi, cầu thang hoặc đèn giao thông. Google bắt đầu loại bỏ dần hệ thống đó từ nhiều năm trước ủng hộ “invisible” reCAPTCHA v3 phân tích tương tác của người dùng thay vì đưa ra thách thức rõ ràng.
Mặc dù vậy, reCAPTCHA v2 cũ hơn là vẫn được sử dụng bởi hàng triệu trang web. Và ngay cả những trang web sử dụng reCAPTCHA v3 được cập nhật đôi khi cũng sẽ như vậy sử dụng reCAPTCHA v2 làm dự phòng khi hệ thống cập nhật cung cấp cho người dùng xếp hạng độ tin cậy “human” thấp.
Nói YOLO với CAPTCHA
Để chế tạo một bot có thể đánh bại reCAPTCHA v2, các nhà nghiên cứu đã sử dụng một phiên bản tinh chỉnh của mô hình nhận dạng đối tượng YOLO (“You Only Look Once”) mã nguồn mở, mà độc giả lâu năm có thể nhớ cũng đã được sử dụng trong các bot gian lận trò chơi điện tử. Các nhà nghiên cứu cho biết mô hình YOLO “nổi tiếng với khả năng phát hiện các vật thể trong thời gian thực” và “có thể được sử dụng trên các thiết bị có sức mạnh tính toán hạn chế, cho phép người dùng độc hại tấn công quy mô lớn.”
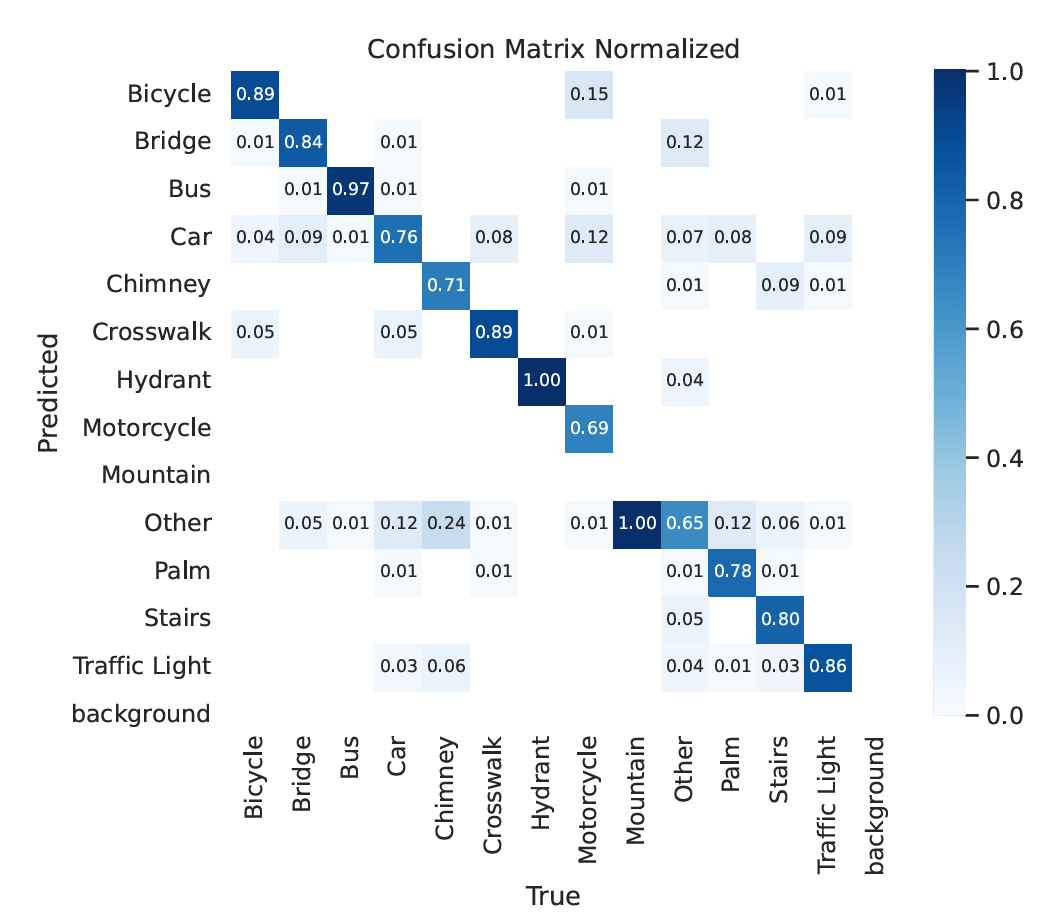
Sau khi đào tạo mô hình trên 14.000 hình ảnh giao thông được gắn nhãn, các nhà nghiên cứu đã có một hệ thống có thể xác định xác suất rằng bất kỳ hình ảnh lưới CAPTCHA nào được cung cấp đều thuộc về một trong 13 danh mục ứng cử viên của reCAPTCHA v2’s. Các nhà nghiên cứu cũng sử dụng một mô hình YOLO riêng biệt, được đào tạo trước cho những gì họ gọi là thử thách “loại 2”, trong đó CAPTCHA yêu cầu người dùng xác định phần nào của một hình ảnh được phân đoạn duy nhất chứa một loại đối tượng nhất định (mô hình phân đoạn này chỉ hoạt động trên chín trong số 13 loại đối tượng và chỉ yêu cầu một hình ảnh mới khi được trình bày cùng với bốn loại còn lại).