GB300 Blackwell Ultra: Tăng 45% hiệu suất DeepSeek-R1 so với GB200
GB300 Blackwell Ultra: NVIDIA công bố bước nhảy 45% hiệu năng để thống trị MLPerf
Giới thiệu
NVIDIA gần đây vừa công bố kết quả benchmark của hệ thống GB300 NVL72 dùng kiến trúc Blackwell Ultra, cho thấy hiệu suất DeepSeek-R1 (benchmark inference reasoning mới trong MLPerf v5.1) tăng 45% so với hệ thống GB200 NVL72 dùng kiến trúc Blackwell trước đó. Đây không phải là con số “xác suất quảng cáo” — NVIDIA cho biết họ đạt được điều này bằng việc kết hợp nâng cấp phần cứng và tối ưu phần mềm chặt chẽ. 
Điều này đánh dấu một bước tiến quan trọng khi NVIDIA đưa Blackwell Ultra vào cuộc chơi inference AI tại datacenter, đồng thời củng cố tham vọng “AI factories” nơi hiệu suất inference quy mô lớn quyết định hiệu quả kinh tế.
Những cải tiến phần cứng & phần mềm giúp GB300 vượt trội
Nâng cấp phần cứng
Blackwell Ultra cung cấp 1,5× lượng compute AI trong định dạng NVFP4 so với Blackwell trước đó.
Tăng khả năng xử lý lớp attention (attention-layer) gấp 2× so với kiến trúc Blackwell tiêu chuẩn.
Mỗi GPU trong GB300 có thể hỗ trợ tới 288 GB HBM3e, gia tăng băng thông và dung lượng nhớ nhanh cho các tác vụ inference lớn.
Kết nối nội bộ giữa GPU (NVLink fabric) hỗ trợ tổng băng thông 130 TB/s qua 1,8 TB/s mỗi liên kết NVLink giữa các GPU, cho phép mở rộng mô hình lớn hiệu quả.
Tối ưu phần mềm & kỹ thuật inference
NVIDIA tận dụng định dạng NVFP4 (floating point 4-bit) để lượng hóa (quantize) trọng số mô hình, giảm dung lượng dữ liệu và tăng thông lượng tính toán mà vẫn giữ độ chính xác yêu cầu.
Thuật toán phục vụ mô hình (serving) được cải thiện với disaggregated serving, tách riêng công việc context và generation để mỗi GPU/chip có thể tối ưu hóa riêng cho pha của nó.
Các kỹ thuật song song (parallelism) mới, cân bằng tải, và tối ưu giao tiếp (gather/scatter) giúp mô hình lớn như Llama 3.1 405B có thể chạy hiệu quả trong chế độ interactive với độ trễ thấp.
Sử dụng CUDA Graphs trong các vòng decode-only để giảm overhead CPU, cải thiện throughput tổng thể.
Kết quả benchmark nổi bật
Trong chế độ DeepSeek-R1, offline, mỗi GPU GB300 đạt throughput cao hơn 45% so với GB200.
Ở chế độ server của DeepSeek-R1 cũng ghi nhận mức tăng khoảng 25%.
Hệ thống GB300 cũng phá “kỷ lục” với các mô hình khác như Llama 3.1 8B, Llama 3.1 405B, Whisper, trong nhiều chế độ benchmark MLPerf v5.1.
Trên các bài benchmark per-GPU, Blackwell Ultra tiếp tục giữ vị trí dẫn đầu trong các mô hình inference quan trọng.
Ý nghĩa & thách thức
Ưu điểm nổi bật
Với hiệu suất inference cao hơn, các trung tâm AI (AI factories) có thể xử lý nhiều token hơn mỗi giây, giảm chi phí mỗi token và tăng doanh thu tiềm năng.
Các mô hình lớn, dài context, inference real-time sẽ được hỗ trợ tốt hơn, đặc biệt với kỹ thuật disaggregated serving cho phép tối ưu riêng hai giai đoạn context & generation.
NVIDIA củng cố vị thế dẫn đầu trong lĩnh vực inference AI, tạo áp lực lên đối thủ như AMD, Intel, và các hãng accelerator khác.
Những điều cần cân nhắc & rủi ro
Kết quả benchmark do NVIDIA công bố — việc kiểm chứng độc lập cần xem xét cẩn trọng, nhất là khi sử dụng kỹ thuật lượng hóa (quantization) và các tối ưu phần mềm nội bộ.
Disaggregated serving yêu cầu giao tiếp nội hệ thống rất cao; nếu băng thông, độ trễ hoặc quản lý không tốt, có thể có bottleneck chuyển dữ liệu giữa các GPU.
Nvidia cần đảm bảo rằng các phần mềm bên ngoài (framework, model, library) hỗ trợ các kỹ thuật tối ưu mới để mở rộng lợi ích ra thực tế.
Giá thành, chi phí điện, làm mát, hạ tầng NVLink / fabric nội rack sẽ là yếu tố then chốt để quyết định việc áp dụng vào sản xuất thương mại.


Bài viết liên quan

Chiếc điện thoại có thể gập lại tốt nhất bạn có thể mua.
Máy màn hình gập (foldable phone) là thiết bị đặc biệt — chúng thường đắt hơn, nặng hơn điện thoại ...

Cách Cài Đặt Đăng Nhập Bằng Vân Tay Trên Windows 10
Cách Cài Đặt Đăng Nhập Bằng Vân Tay Trên Windows 10 Giới thiệu Sử dụng vân tay để đăng nhập vào máy ...

Độc Quyền: iPhone 17 Pro Quay MLB "Friday Night Baseball" – Bước Chuyển Mình Của Camera Tiêu Dùng Sang Sản Xuất Chuyên Nghiệp
iPhone 17 Pro Phá Vỡ Rào Cản: Lần Đầu Tiên Được Tích Hợp Vào Quy Trình Phát Sóng MLB Chuyên Nghiệp ...
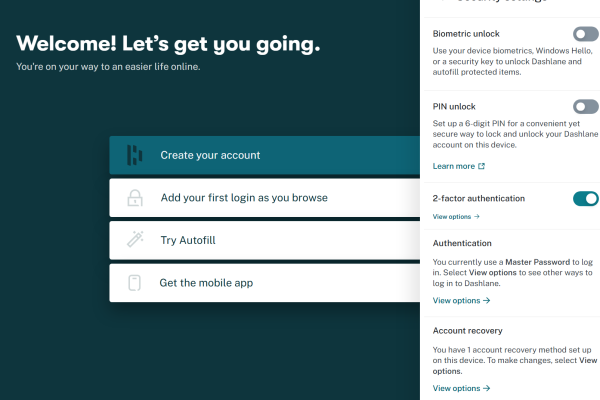
Hướng dẫn thiết lập phương thức khôi phục tài khoản trong Dashlane
Dashlane là một trong những trình quản lý mật khẩu phổ biến, giúp người dùng lưu trữ và bảo mật ...

Đánh giá Asus ROG Strix SCAR 18 (2025): trông tuyệt vời và chơi game cũng tốt
Đánh giá Asus ROG Strix SCAR 18 (2025): trông tuyệt vời và chơi game cũng tốt Ưu điểm Màn hình ...

Những chiếc AirPods tốt nhất để mua
Những chiếc AirPods tốt nhất để mua Dù bạn đang mua cặp AirPods đầu tiên hay thay thế một cặp cũ đã ...