Công cụ tìm kiếm AI Perplexity đang sử dụng bot tàng hình và các chiến thuật khác để trốn tránh các chỉ thị không thu thập dữ liệu của trang web, một cáo buộc rằng nếu true vi phạm các quy tắc Internet đã tồn tại hơn ba thập kỷ, dịch vụ tối ưu hóa và bảo mật mạng Cloudflare cho biết hôm thứ Hai.
Trong một bài blog, các nhà nghiên cứu của Cloudflare cho biết công ty đã nhận được khiếu nại từ những khách hàng không cho phép bot cạo Perplexity bằng cách triển khai cài đặt trong tệp.txt robot sites’ của họ và thông qua tường lửa ứng dụng Web đã chặn trình thu thập thông tin Perplexity đã khai báo. Cloudflare cho biết, bất chấp những bước đó, Perplexity vẫn tiếp tục truy cập nội dung của sites’.
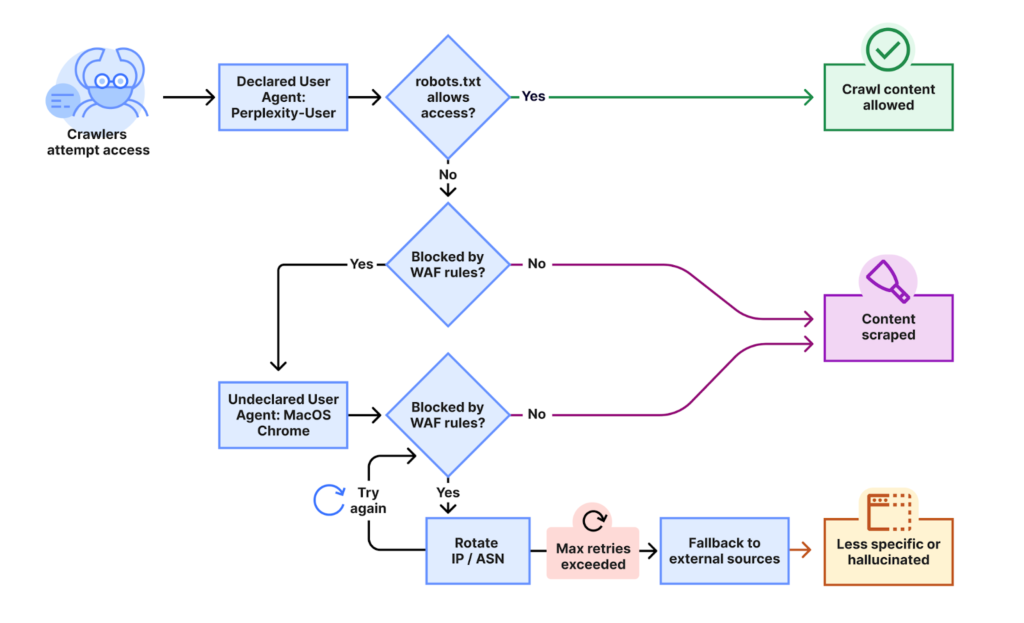
Các nhà nghiên cứu cho biết sau đó họ bắt đầu tự kiểm tra nó và phát hiện ra rằng khi các trình thu thập thông tin Perplexity được biết đến gặp phải các khối từ tệp robots.txt hoặc quy tắc tường lửa, Perplexity sau đó đã tìm kiếm các trang web bằng cách sử dụng bot tàng hình tuân theo một loạt chiến thuật để che giấu hoạt động của nó.
>10.000 tên miền và hàng triệu yêu cầu
“Trình thu thập thông tin không được khai báo này đã sử dụng nhiều IP không được liệt kê trong phạm vi IP chính thức của Perplexity và sẽ xoay qua các IP này để đáp ứng chính sách robots.txt hạn chế và chặn từ Cloudflare, các nhà nghiên cứu viết. “Ngoài việc luân chuyển IP, chúng tôi còn quan sát thấy các yêu cầu đến từ các ASN khác nhau nhằm cố gắng trốn tránh các khối trang web hơn nữa. Hoạt động này được quan sát trên hàng chục nghìn tên miền và hàng triệu yêu cầu mỗi ngày.”
Các nhà nghiên cứu đã cung cấp sơ đồ sau để minh họa quy trình của kỹ thuật mà họ cho là Sự bối rối được sử dụng.