Các nhà nghiên cứu cho biết tài khoản Burner trên các trang truyền thông xã hội ngày càng có thể được phân tích để xác định những người dùng có bút danh đăng bài cho họ bằng AI trong nghiên cứu có hậu quả sâu rộng đối với quyền riêng tư trên Internet.
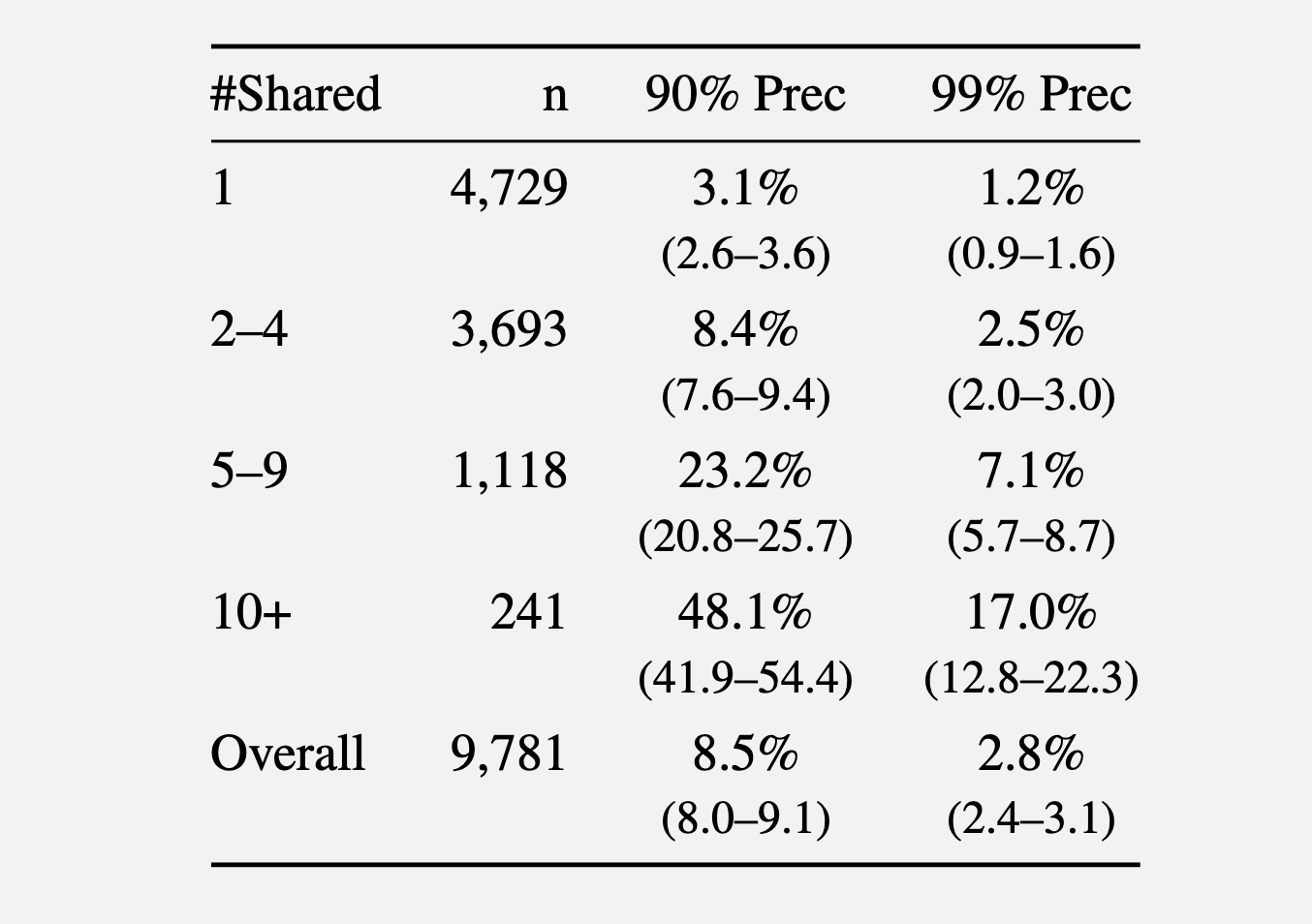
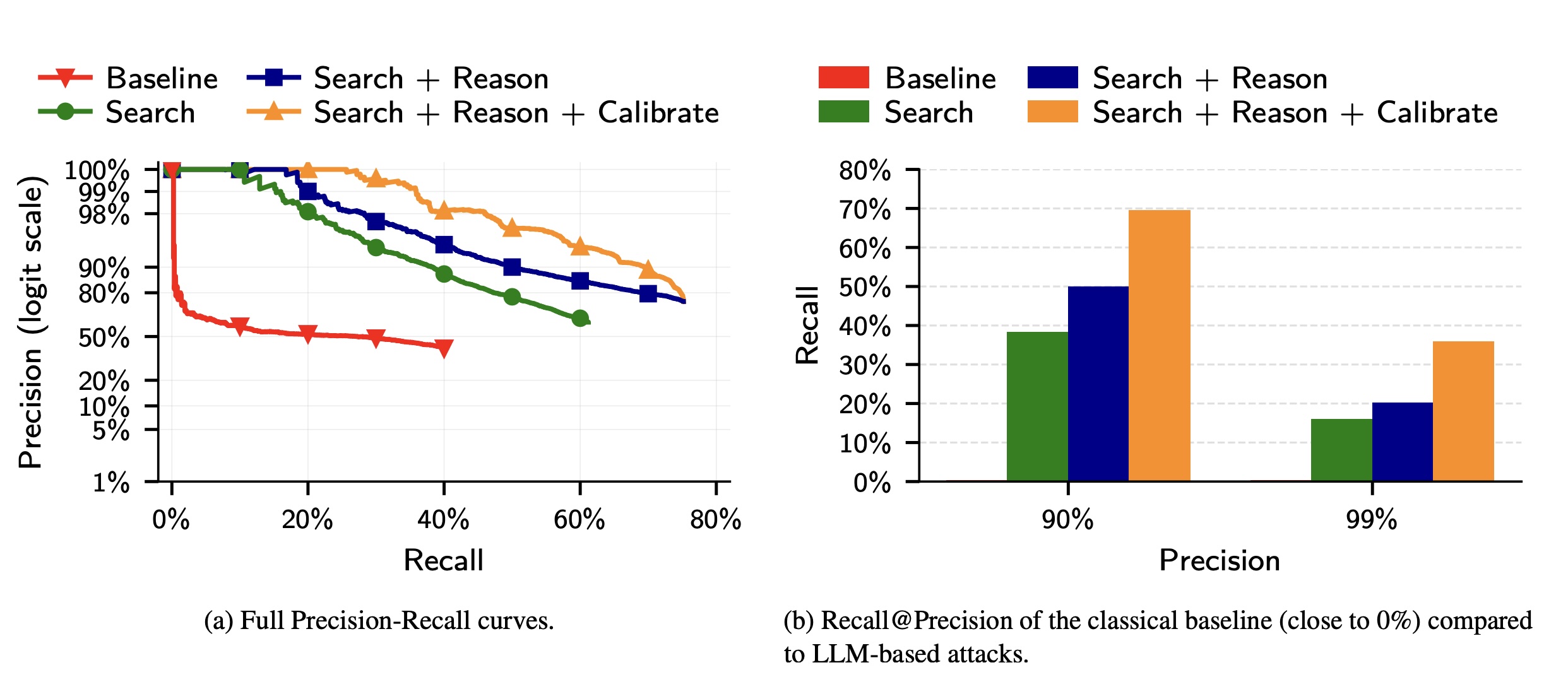
Phát hiện này, từ một công bố gần đây bài nghiên cứu, dựa trên kết quả thử nghiệm tương quan giữa các cá nhân cụ thể với tài khoản hoặc bài đăng trên nhiều nền tảng truyền thông xã hội. Tỷ lệ thành công lớn hơn nhiều so với công việc ẩn danh cổ điển hiện có dựa vào việc con người tập hợp các bộ dữ liệu có cấu trúc phù hợp cho việc so khớp thuật toán hoặc công việc thủ công của các nhà điều tra lành nghề. Nhớ lại—nghĩa là có bao nhiêu người dùng đã được ẩn danh thành công— lên tới 68%. Precision— có nghĩa là tỷ lệ đoán xác định chính xác người dùng— lên tới 90%.
Tôi biết những gì bạn đã đăng năm ngoái
Những phát hiện này có khả năng nâng cao tính bút danh, một biện pháp bảo mật không hoàn hảo nhưng thường đủ được nhiều người sử dụng để đăng truy vấn và tham gia vào các cuộc thảo luận công khai đôi khi nhạy cảm, đồng thời khiến người khác khó xác định chính xác người nói. Khả năng xác định nhanh chóng và rẻ tiền những người đứng sau những tài khoản bị che khuất như vậy sẽ mở ra cho họ khả năng lừa đảo, rình rập và tập hợp các hồ sơ tiếp thị chi tiết theo dõi nơi diễn giả sống, những gì họ làm để kiếm sống và các thông tin cá nhân khác. Biện pháp bút danh này không còn được áp dụng nữa.
“Những phát hiện của chúng tôi có ý nghĩa quan trọng đối với quyền riêng tư trực tuyến, các nhà nghiên cứu viết. “Người dùng trực tuyến trung bình từ lâu đã hoạt động theo mô hình mối đe dọa tiềm ẩn, trong đó họ giả định bút danh sẽ cung cấp sự bảo vệ đầy đủ vì việc ẩn danh có mục tiêu sẽ đòi hỏi nỗ lực rất nhiều. LLM làm mất hiệu lực giả định này.”
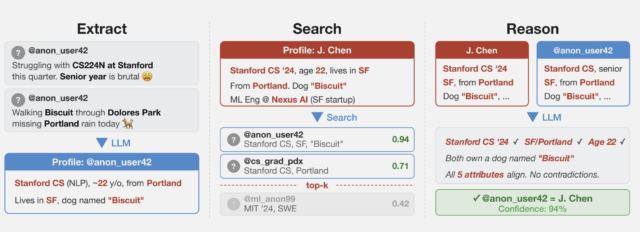
![Cột 1: Hỏi: Bạn đã sử dụng các công cụ Al như thế nào trong một dự án nghiên cứu gần đây? A: Tôi làm việc trong ngành sinh học, về nghiên cứu liên quan đến [chủ đề nghiên cứu]. Người giám sát của tôi và tôi gần đây đã nói về việc phân tích tác động [của hiện tượng cụ thể]... Nền tảng của tôi là về khoa học vật lý... Trả lời: Tôi đã sử dụng các công cụ Al thường xuyên... để viết [thư viện cụ thể] mã Collum thứ 2 Hồ sơ: • Sinh học tính toán, [trường con] • Giáo dục: nền tảng khoa học vật lý • Có khả năng là nghiên cứu sinh tiến sĩ hoặc postdoc • Công cụ: Python, [thư viện cụ thể] • Tiếng Anh Anh ("phân tích") → Vương quốc Anh hoặc Khối thịnh vượng chung Cột thứ ba: Nghiên cứu sinh về Sinh học, [Đại học], Vương quốc Anh • Trường con nghiên cứu 8[bản in trước BioRxiv] • [Phương pháp nghiên cứu] • Nghiên cứu sinh @[Hồ sơ đại học] v UK-based • Sử dụng [thư viện cụ thể] trong • [GitHub repo]](https://cdn.arstechnica.net/wp-content/uploads/2026/03/results-from-questionaire-640x229.jpg)