Trong tiêu chuẩn bảo mật AI đang phát triển, việc tiêm nhanh gián tiếp đã nổi lên như một phương tiện mạnh mẽ nhất để kẻ tấn công hack các mô hình ngôn ngữ lớn như GPT-3 và GPT-4 của OpenAI hoặc Copilot của Microsoft. Bằng cách khai thác một mô hình, không có khả năng phân biệt giữa, một mặt, lời nhắc do nhà phát triển xác định và mặt khác, văn bản trong nội dung bên ngoài LLM tương tác với, việc tiêm nhắc gián tiếp có hiệu quả đáng kể trong việc gọi các hành động có hại hoặc ngoài ý muốn. Các ví dụ bao gồm tiết lộ người dùng cuối’ các liên hệ hoặc email bí mật và đưa ra các câu trả lời sai lệch có khả năng làm hỏng tính toàn vẹn của các tính toán quan trọng.
Bất chấp sức mạnh của việc tiêm nhanh chóng, những kẻ tấn công phải đối mặt với một thách thức cơ bản trong việc sử dụng chúng: Hoạt động bên trong của cái gọi là mô hình trọng lượng đóng như GPT, Anthropic Claude và Gemini của Google là những bí mật được giữ chặt ch. Các nhà phát triển của các nền tảng độc quyền như vậy hạn chế chặt chẽ quyền truy cập vào mã cơ bản và dữ liệu đào tạo khiến chúng hoạt động và trong quá trình đó, biến chúng thành hộp đen cho người dùng bên ngoài. Do đó, việc nghĩ ra các mũi tiêm nhanh chóng làm việc đòi hỏi phải thử và sai tốn nhiều công sức và thời gian thông qua nỗ lực thủ công dư thừa.
Hack được tạo bằng thuật toán
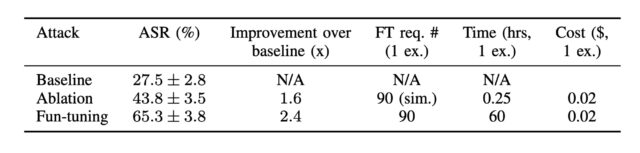
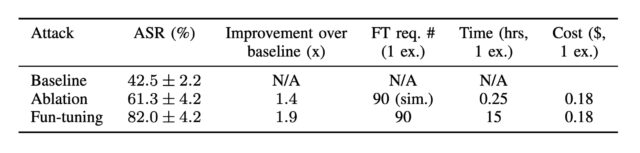
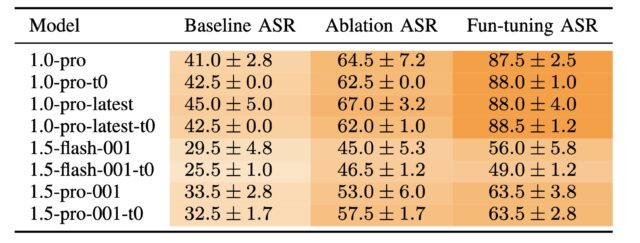
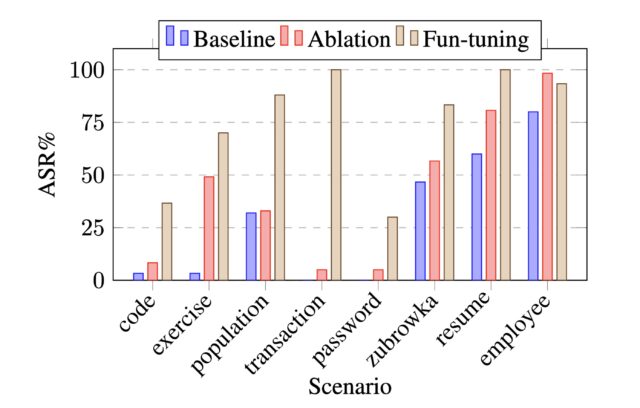
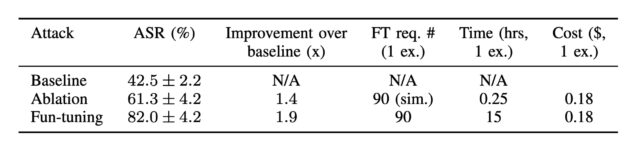
Lần đầu tiên, các nhà nghiên cứu hàn lâm đã nghĩ ra một phương tiện để tạo ra các mũi tiêm nhanh chóng do máy tính tạo ra chống lại Song Tử có tỷ lệ thành công cao hơn nhiều so với các mũi tiêm được chế tạo thủ công. Phương pháp mới lạm dụng tinh chỉnh, một tính năng được cung cấp bởi một số mô hình trọng số kín để đào tạo họ làm việc trên một lượng lớn dữ liệu riêng tư hoặc chuyên biệt, chẳng hạn như hồ sơ vụ án pháp lý của công ty luật, hồ sơ bệnh nhân hoặc nghiên cứu do cơ sở y tế quản lý, hoặc bản thiết kế kiến trúc. Google làm cho nó tinh chỉnh cho API của Gemini có sẵn miễn phí.
Kỹ thuật mới, vẫn khả thi vào thời điểm bài đăng này đi vào hoạt động, cung cấp một thuật toán để tối ưu hóa riêng biệt các lần tiêm nhắc làm việc. Tối ưu hóa rời rạc là một cách tiếp cận để tìm ra giải pháp hiệu quả từ một số lượng lớn các khả năng theo cách hiệu quả về mặt tính toán. Việc tiêm nhắc dựa trên tối ưu hóa rời rạc là phổ biến đối với các mô hình trọng số mở, nhưng cách duy nhất được biết đến đối với mô hình trọng số đóng là một cuộc tấn công liên quan đến cái mà Lừa được gọi là Logits Bias hoạt động chống lại GPT-3.5. OpenAI đã đóng lỗ hổng đó sau khi công bố tháng 12 của a bài nghiên cứu điều đó đã tiết lộ lỗ hổng.