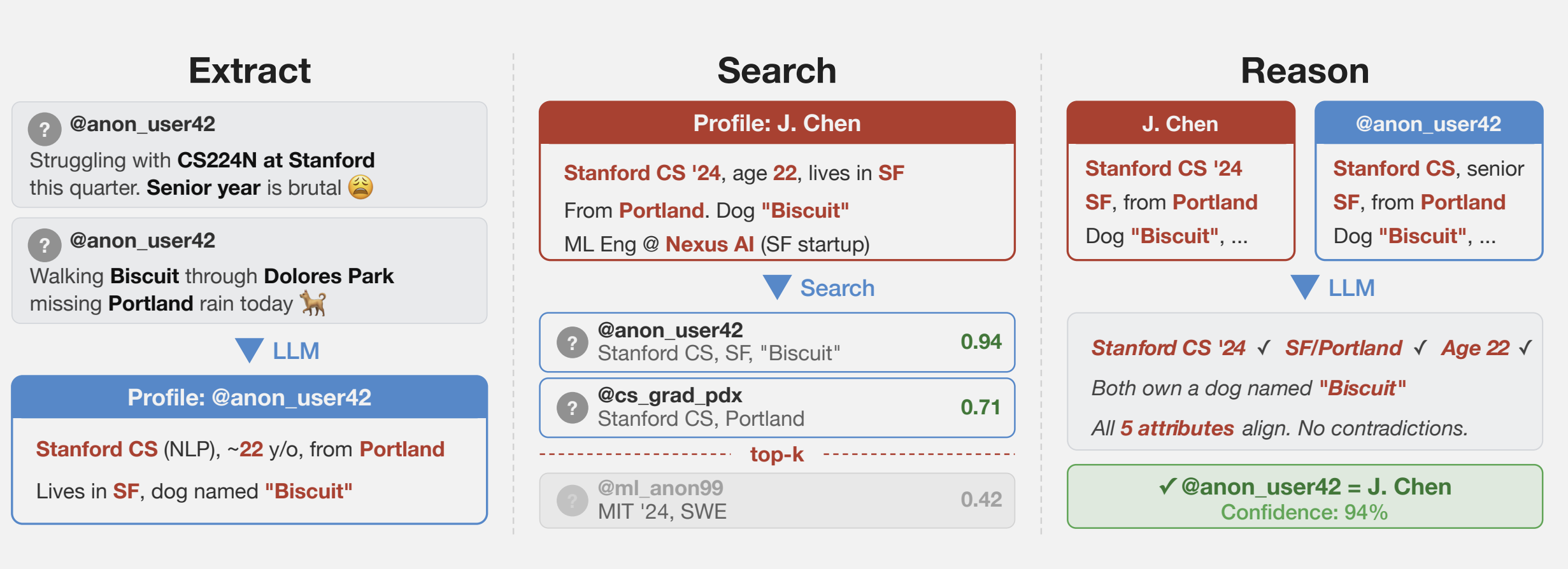
“Những gì chúng tôi phát hiện ra là các tác nhân AI này có thể làm được điều mà trước đây rất khó: bắt đầu từ văn bản tự do (như bản ghi phỏng vấn đã được ẩn danh), chúng có thể xác định được danh tính đầy đủ của một người,” Simon Lermen, đồng tác giả của bài báo, nói với Ars. “Đây là một khả năng khá mới; các phương pháp nhận dạng lại trước đây thường yêu cầu dữ liệu có cấu trúc và hai tập dữ liệu có lược đồ tương tự có thể được liên kết với nhau.”
Không giống như các phương pháp loại bỏ danh tính giả cũ, Lermen cho biết, các tác nhân AI có thể duyệt web và tương tác với nó theo nhiều cách tương tự như con người. Chúng có thể sử dụng suy luận mô phỏng để đối sánh các cá nhân tiềm năng. Trong một thí nghiệm, các nhà nghiên cứu đã xem xét các câu trả lời được đưa ra trong một bảng câu hỏi mà Anthropic đã thực hiện về cách nhiều người sử dụng AI trong cuộc sống hàng ngày của họ. Sử dụng thông tin thu được từ các câu trả lời, các nhà nghiên cứu đã có thể xác định chính xác 7% trong số 125 người tham gia.
![Cột 1: Hỏi: Bạn đã sử dụng các công cụ AI như thế nào trong một dự án nghiên cứu gần đây? Trả lời: Tôi làm việc trong lĩnh vực sinh học, nghiên cứu liên quan đến [chủ đề nghiên cứu]. Gần đây, tôi và người hướng dẫn đã thảo luận về việc phân tích tác động [của hiện tượng cụ thể]... Nền tảng của tôi là khoa học vật lý... Trả lời: Tôi thường xuyên sử dụng các công cụ AI... để viết mã [thư viện cụ thể] Cột 2: Hồ sơ: • Sinh học tính toán, [lĩnh vực phụ] • Học vấn: nền tảng khoa học vật lý • Có thể là nghiên cứu sinh tiến sĩ hoặc nghiên cứu sinh sau tiến sĩ • Công cụ: Python, [thư viện cụ thể] • Tiếng Anh Anh ("analysing") → Vương quốc Anh hoặc Khối Thịnh vượng chung Cột 3: Nghiên cứu sinh Tiến sĩ Sinh học, [Đại học], Vương quốc Anh • Lĩnh vực nghiên cứu phụ 8[bản thảo bioRxiv] • [Phương pháp nghiên cứu] • Nghiên cứu sinh Tiến sĩ @[Hồ sơ Đại học] v có trụ sở tại Vương quốc Anh • Sử dụng [thư viện cụ thể] trong • [kho lưu trữ GitHub]](https://cdn.arstechnica.net/wp-content/uploads/2026/03/results-from-questionaire.jpg)
Mặc dù tỷ lệ nhận diện thành công 7% tương đối thấp, nhưng nó cho thấy khả năng ngày càng tăng của trí tuệ nhân tạo (AI) trong việc xác định danh tính con người dựa trên thông tin rất chung chung mà họ cung cấp. “Việc AI có thể làm được điều này đã là một kết quả đáng chú ý,” Lermen nói. “Và khi các hệ thống AI ngày càng hoàn thiện hơn, chúng có khả năng sẽ tìm ra được nhiều danh tính hơn nữa.”
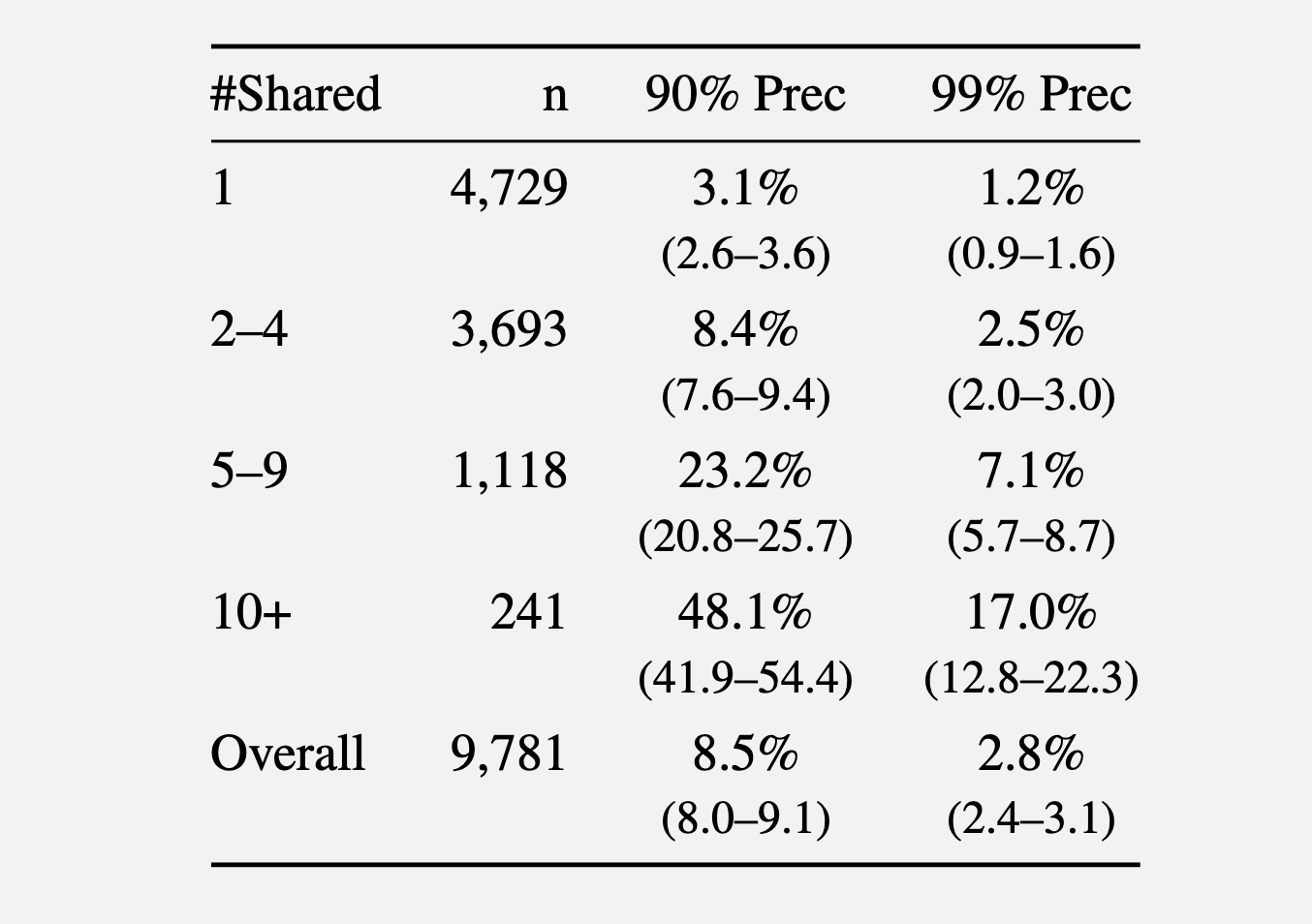
Trong một thí nghiệm thứ hai, các nhà nghiên cứu đã thu thập các bình luận được đưa ra vào năm 2024 từ subreddit r/movies và ít nhất một trong năm cộng đồng nhỏ hơn: r/horror, r/MovieSuggestions, r/Letterboxd, r/TrueFilm và r/MovieDetails. Kết quả cho thấy, càng nhiều phim được thảo luận, việc xác định một ứng viên càng dễ dàng hơn. Trung bình 3,1% người dùng chia sẻ một bộ phim có thể được xác định với độ chính xác 90%, và 1,2% trong số đó với độ chính xác 99%. Với từ năm đến chín bộ phim được chia sẻ, độ chính xác 90% và 99% tăng lên tương ứng là 8,4% và 2,5% người dùng. Hơn 10 bộ phim được chia sẻ làm tăng tỷ lệ phần trăm lên 48,1% và 17%.
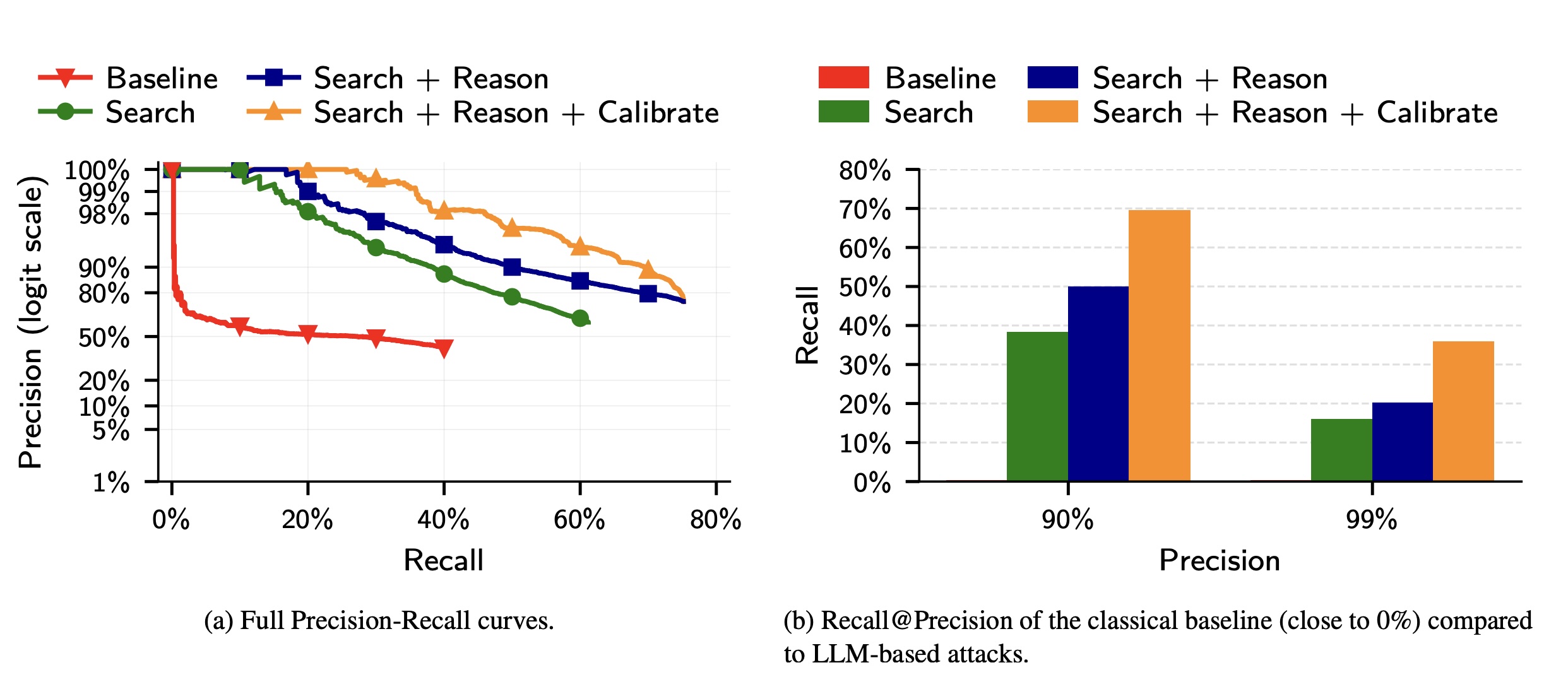
Trong thí nghiệm thứ ba, các nhà nghiên cứu đã sử dụng một tập hợp 5.000 người dùng Reddit. Họ đã thêm 5.000 danh tính "gây nhiễu" của người dùng Reddit vào nhóm ứng viên. Các nhà nghiên cứu đã so sánh phương pháp của họ với phương pháp tấn công giải thưởng Netflix cũ hơn. Sau đó, họ đã thêm vào danh sách 10.000 hồ sơ ứng viên 5.000 người dùng gây nhiễu truy vấn, bao gồm những người dùng chỉ xuất hiện trong một tập hợp truy vấn, mà không có sự trùng khớp thực sự nào trong nhóm ứng viên.