Maindola nói với Ars rằng “bộ dữ liệu đã bị đánh dấu là thuộc phạm vi công cộng do nhầm lẫn. Không có ý định xuyên tạc tình trạng cấp phép của các tác phẩm.”
Không rõ liệu Kamath được yêu cầu liên kết đến bộ dữ liệu sách Harry Potter trong bài đăng trên blog hay đó là lựa chọn cá nhân của ông. Cathay YN Smith, giáo sư luật và đồng giám đốc Chương trình Luật Sở hữu Trí tuệ của Trường Luật Chicago-Kent, nói với Ars rằng Kamath có thể không nhận ra rằng những cuốn sách đó mới xuất bản gần đây nên chưa thuộc phạm vi công cộng.
“Một người có thể rất am hiểu về sách và công nghệ, nhưng không nhất thiết phải am hiểu về các điều khoản bản quyền và thời hạn hiệu lực của chúng,” Smith nói. “Đặc biệt là nếu người đó thấy rằng một tác phẩm nào đó đã được một công ty uy tín khác đánh dấu là thuộc phạm vi công cộng.”
Microsoft từ chối yêu cầu bình luận từ Ars. Kaggle cũng không phản hồi yêu cầu bình luận từ Ars.
Microsoft "có lẽ đã khôn ngoan" khi gỡ bỏ bài đăng trên blog.
Trên Hacker News, các bình luận viên cho rằng khó có ai quen thuộc với loạt phim nổi tiếng này tin rằng sách Harry Potter thuộc phạm vi công cộng. Họ tranh luận liệu bài đăng trên blog của Microsoft có "gây vấn đề về bản quyền" hay không, vì Microsoft không chỉ khuyến khích khách hàng tải xuống các tài liệu vi phạm bản quyền mà còn sử dụng chính những cuốn sách đó để tạo ra các mô hình AI Harry Potter dựa trên các nhân vật được yêu thích để quảng bá sản phẩm của Microsoft.
Bài đăng trên blog của Microsoft được đăng tải cách đây hơn một năm, vào thời điểm các công ty AI bắt đầu phải đối mặt với các vụ kiện liên quan đến các mô hình AI, bị cáo buộc vi phạm bản quyền bằng cách huấn luyện trên các tài liệu lậu và sao chép nguyên văn các tác phẩm.
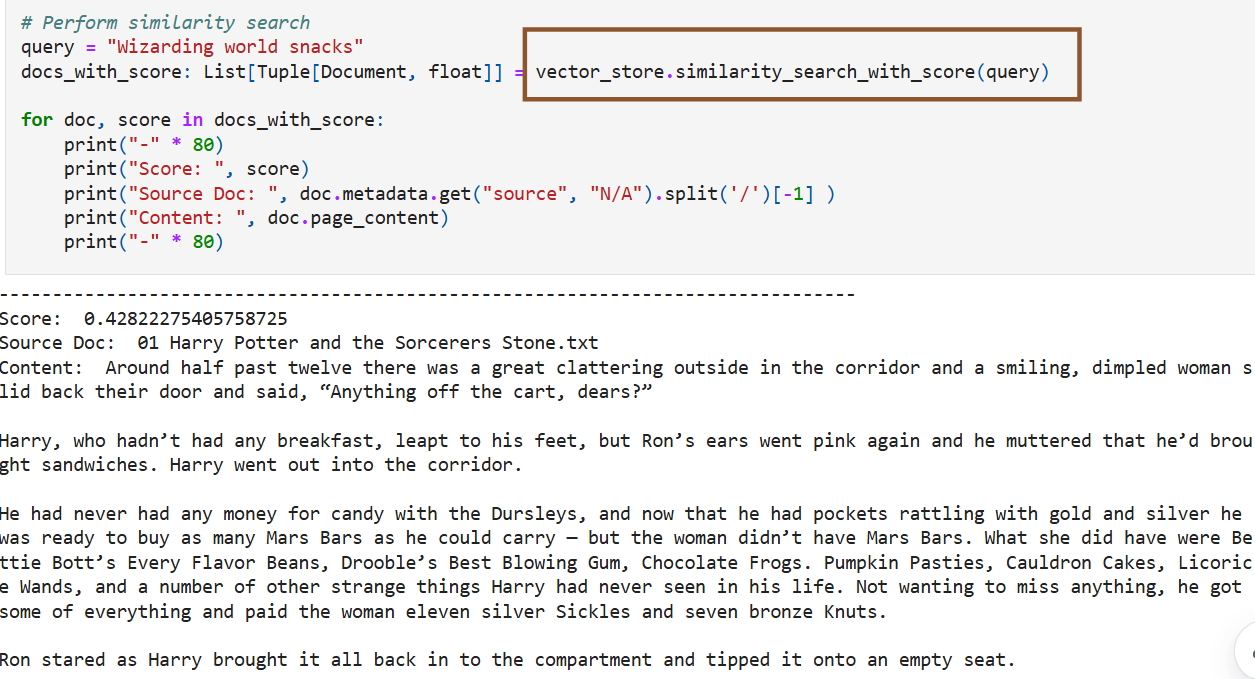
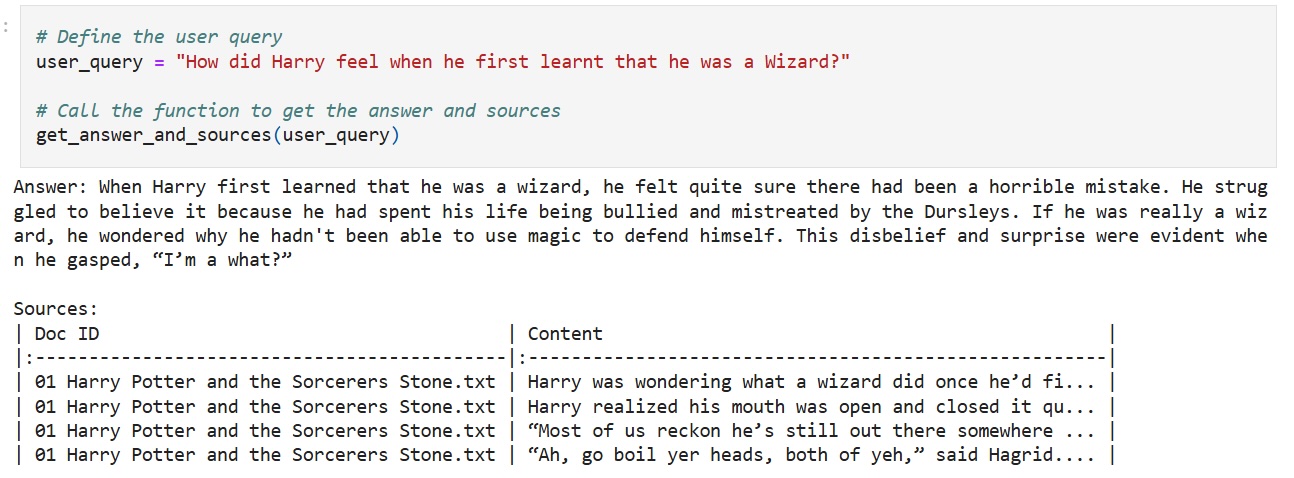
Bài đăng trên blog khuyên người dùng nên học cách huấn luyện mô hình AI của riêng mình bằng cách tải xuống bộ dữ liệu Harry Potter và sau đó tải các tệp văn bản lên Azure Blob Storage. Bài đăng bao gồm các mô hình ví dụ dựa trên bộ dữ liệu mà Microsoft dường như đã tải lên Azure Blob Storage, chỉ bao gồm cuốn sách đầu tiên, Harry Potter và Hòn đá phù thủy .