Nvidia khẳng định H100 vượt MI300X khoảng 2× khi tối ưu đúng cách

Trong tuyên bố mới đây, Nvidia đáp trả các khẳng định của AMD về hiệu năng GPU MI300X, cho rằng nếu cấu hình và tối ưu phần mềm đúng cách, GPU H100 có thể đạt hiệu năng gấp đôi so với MI300X trong các tác vụ inference. Theo Nvidia, kết quả so sánh ban đầu do AMD công bố không sử dụng đầy đủ các tối ưu của TensorRT-LLM, vốn hỗ trợ những kernel được tinh chỉnh đặc biệt cho kiến trúc Hopper.
Cụ thể, Nvidia nhấn mạnh rằng trong thử nghiệm với mô hình Llama 2 70B, một hệ thống DGX H100 (8 GPU) chỉ mất khoảng 1,7 giây cho một phép inference đơn (batch size = 1), trong khi với MI300X 8 GPU, thời gian là 2,5 giây theo dữ liệu mà Nvidia trích dẫn từ AMD. Với cách đo “response time cố định” được nhiều dịch vụ cloud sử dụng — tức nếu thời gian đáp ứng được giữ ổn định, thiết bị có thể xử lý nhiều truy vấn hơn — Nvidia cho rằng hệ thống H100 sẽ xử lý được “hơn 5 inference mỗi giây” trong cấu hình 8 GPU, vượt trội so với MI300X trong cùng setup tương ứng.
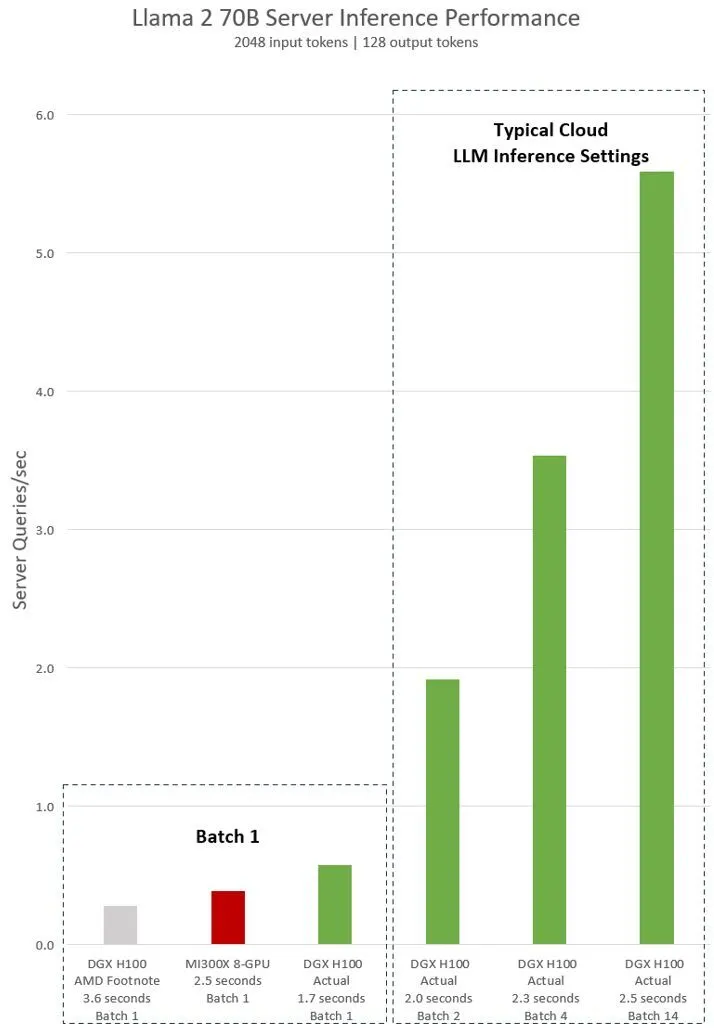
Nvidia còn cho rằng các bản trình diễn của AMD không bao gồm các tối ưu kernel đặc thù cho kiến trúc Hopper, và việc sử dụng TensorRT-LLM là yếu tố then chốt để khai thác hiệu năng cao nhất của H100. Theo Nvidia, đây là lý do khiến hiệu suất thực tế của H100 trong các bài so sánh có thể bị “bóp” nếu không được tối ưu đúng cách.
Tuy nhiên, các nhận định này đều dựa vào dữ liệu do Nvidia công bố và so sánh theo cách họ chọn. Độc giả và giới chuyên môn vẫn lưu ý rằng hiệu năng cuối cùng còn phụ thuộc vào nhiều yếu tố: phần mềm, cách cấu hình, kích thước batch, mô hình AI sử dụng, và khả năng tối ưu từ AMD cũng như khả năng tối ưu của MI300X khi được test đúng cách.



Bài viết liên quan

Pixel 10 Pro Fold, Project Amethyst và những bất ngờ công nghệ mới nhất
Chào mừng bạn đến với bản tin công nghệ hôm nay, nơi chúng ta điểm qua những sản phẩm mới, công nghệ ...
Chú hề Pennywise trở lại trong loạt phim tiền truyện It: Welcome to Derry của HBO
HBO vừa phát hành trailer chính thức cho It: Welcome to Derry , loạt phim tiền truyện của It (2017) ...

SpaceX công bố ngày thử nghiệm thứ 11 của Starship – Cách theo dõi
SpaceX đã thông báo dự kiến thứ Hai, ngày 13 tháng 10 , sẽ diễn ra chuyến bay thử thứ 11 của tên lửa ...

Tesla, Warner Bros. né tránh một số khiếu nại trong vụ kiện 'Blade Runner 2049', cuộc chiến bản quyền vẫn tiếp diễn
Tesla, Warner Bros. né tránh một số khiếu nại trong vụ kiện 'Blade Runner 2049', cuộc chiến bản ...

Con người có thể kết hôn với AI không? Một tiểu bang ở Mỹ muốn vạch ra ranh giới
Con người có thể kết hôn với AI không? Một tiểu bang ở Mỹ muốn vạch ra ranh giới Ohio Đề Xuất Cấm ...

Tai nghe Sony WH-1000XM6 tuyệt vời nay đã trở nên tốt hơn
Chuyện gì đã xảy ra? Sony đã bắt đầu tung ra bản cập nhật phần mềm cho tai nghe cao cấp WH-1000XM6 , ...